
网页索引增加的10种办法
一般来说正常的网站内容都能够被谷歌搜索引擎收录并添加到其索引数据库中,只不过每个网站页面可能因为页面质量、搜索用户体验、网站域名权重等因素的影响会导致被索引的时间存在一定的差异。但实际情况下,很多同学还是在为自己的网站页面迟迟不能被谷歌索引而感到头疼。那么,今天Jack老师就和大家一起来学习一下 网页索引增加的10种方法 。
方法一:删除 robots.txt 文件中禁止爬取代码
robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。那么这个文件怎么设置或者改写呢?通过ftp软件远程连接或者直接登录直接网站的后台服务器,找到根目录下的该文件,然后进行改写。
我们再来看一下robots.txt文件的写法:
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以”.htm”为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以”.htm”为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
比方说我们要禁止百度的蜘蛛来爬取我们网站的页面内容,那robots.txt文件应该怎么写呢?如下所示。
User-agent: Baiduspider
Disallow: /
如果我们又突然改变主意,想允许它爬取我们的内容,又该怎么写呢?如下所示。
User-agent: Baiduspider
Allow: /
方法二:移除noindex代码
但我们在做wordpress网站的时候,一般会在设置中的阅读功能下设置“暂不对搜索引擎可见”,这时候如果你去查看网站任何一个页面的源代码(用ctrl+u快捷键,或者鼠标右键点击查看网页源代码),你会在源代码中看到noindex的存在。
这个代码告诉了搜索引擎不要将该页面内容添加到谷歌的索引数据库中。在做完网站之后,我们很可能忘记了最初的这个网站功能设置,导致自己的网站页面迟迟的不能被索引。所以在网站内容检查无误准备放开收录的时候,这里的功能一定要取消,如下图所示。

还有一种noindex的情况比较特殊,那就是X‑Robots-Tag标头。X-Robots-Tag 可用作指定网址的 HTTP 标头响应中的一个元素。可在漫游器元标记中使用的任何指令均可被指定为 X-Robots-Tag。下面是一个 HTTP 响应示例,它含有一个指示抓取工具不要将某一网页编入索引的 X-Robots-Tag:

这一点可能对同学们比较陌生,我们可以使用Ahrefs工具的“站点审核工具”来进行操作,如下图所示。

如果对这个项目不是很明白的同学,建议先点击查看一下这方面的知识,链接如下
漫游器元标记知识拓展入口
方法三:在站点地图中包含该页面
站点地图告诉 Google 你网站上的哪些页面重要,哪些不重要。它还可能会就应重新抓取它们的频率提供一些指导。Google 应该能够在你的网站上找到页面,无论它们是否在你的站点地图中,但将它们包含在内仍然是一种很好的做法。
毕竟,让谷歌的抓取工作变得困难是没有意义的。要检查某个页面是否在你的站点地图中,请使用Search Console 中的网址检查工具。如果你看到“网址不在 Google 上”错误和“站点地图:不适用”这些报错情况,那么说明某个网站页面不在你的站点地图中或尚未编入索引。
一般来说,如果你安装了yoast seo或者math rank等谷歌SEO优化插件,它们都会为你主动生成网站的sitemap,你只需要将这些sitemap主动提交到网站的google search console中即可。提交完成之后,你可以顺手做一个ping提交指令,如下所示:
https://www.google.com/ping?sitemap=http://www.domain.com/sitemap_url.xml
方法四:删除流氓规范标签
规范标签告诉 Google 哪个是页面的首选版本。它看起来像这样:
<link rel="canonical” href="/page.html/">
大多数页面要么没有规范标签,要么没有所谓的自引用规范标签。这告诉 Google 页面本身是首选的,也可能是唯一的版本。换句话说,你希望谷歌搜索引擎将此页面编入索引。但是,如果你的页面有一个流氓规范标签,那么它可能会告诉 Google 该页面的首选版本不存在。
在这种情况下,你的页面不会被编入索引。如果你想要检查URL网址规范,那么请使用 Google 的URL检查工具。如果规范指向另一个页面,那么你将会看到“带有规范标记的备用页面”警告,如下所示。
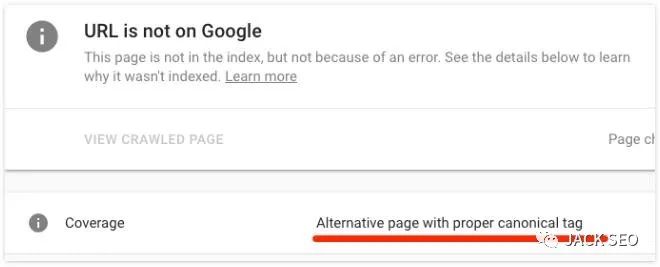
需要注意的是:规范标签并不总是坏的。大多数带有这些标签的页面都会有它们。如果看到你的页面具有规范集,请检查规范页面。如果这确实是页面的首选版本,并且不需要为相关页面建立索引,那么规范标签应该保留。
方法五:检查孤立页面
孤立页面是那些没有内部链接指向它们的页面。或者说当前的某个页面没有任何的链接方式通往自己网站的其他页面。常见于一些landing page页面,甚至都没有菜单导航栏的存在。
由于 Google 通过抓取网络来发现新内容,因此他们无法通过该过程发现孤立页面。网站访问者也无法找到它们。要检查孤立页面,可以使用Ahrefs 的站点审核来抓取网站页面。然后检查 “孤立页面(没有传入的内部链接)”错误的链接报告,如下图所示。

当然了,市面上还是有很多其他的url检测工具也有非常强大的功能,比方说尖叫青蛙,Check box等等。利用这些工具也能够为自己的网站检测出没有做任何链接指向其他页面的“孤立页面”。
好了,以上就是 网页索引增加的10种办法 上半部分的内容,下半部分内容将在下一章节中进行讲解,敬请期待。
如果对本章内容还有不理解的地方,没关系,解决方案如下:
百度或者谷歌浏览器搜索 “JACK外贸建站”,排名首页首位的就是我的网站。网站上有更多免费的外贸建站、谷歌SEO优化、外贸客户开发等实操干货知识等着你哦!
(各位看官老爷,都看到这里了,就麻烦动动金手点击转发一下本文到自己的微信朋友圈吧,转发过程如下)
QQ:3233269705
QQ群:645296397
微信公众号:JACK SEO

文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)





发表评论 取消回复